

The Beta-Geometric Negative Binomial Distribution (BG-NBD) model is an influential probabilistic model for describing customer behavior and for predicting customer lifetime value (CLV)¹. In the previous article of the series, we've explored the intuition, assumptions and mathematical derivation of this model. I’d suggest you take a look at it if you haven’t!
As you might have inferred from that article, it’s not easy to code all those BG-NBD equations manually. Luckily, there is a Python library called lifetimes that can do all the heavy lifting for us. lifetimes abstracts away the internal complexity of BG-NBD and allows us to focus on deriving insights and business values out of the model.
This awesome library was created by Cam-Davidson Pillon, who is also the author of the book Probabilistic Programming & Bayesian Methods for Hackers, a must-read for all Bayesian enthusiasts.
This article explores the ins and outs of lifetimes. Here is our agenda:
Let’s get started!
Usually, businesses record their transactions in a “transactions” table. Such a table has rows that represent individual transactions and columns that present different aspects of the transactions such as the customer involved, the timestamp of the transaction and its value. An example transactions table is provided by lifetimes. This table records the transactions of CDNow, a dot-com era company that sold CDs and music products. It contains 6,919 transactions from 2,357 customers from 1 January 1997 to 30 June 1998 (a total of 78 weeks). We'll be using it throughout this article. Here is how to load it:

Before fitting the BG-NBD model, we need to first restructure this table to the canonical “RFM” format. A table in the RFM format has rows that represent individual customers and the following columns:

lifetimes provides a utility function that facilitates the conversion from the "transactions" format to the RFM format.

The way we’d interpret the first row of the RFM dataframe is as follows:
Note that when a zero value for the frequency, recency and monetary_value columns (such as for customer 18) indicates that the customer only made 1 purchase in the observation period.
When reformating our table into the RFM format, we have the option to also perform a calibration-holdout split, which is similar in spirit to the train-test split procedure we’re all familiar with. The calibration-holdout split divides our transactions into two depending on whether they fall into the calibration period or the observation period. The transactions that took place during the calibration period are used to train the model, whereas those occurring during the observation period (“holdout’” transactions) are used to validate the model.

In this example, we’ll set the calibration and the observation periods to be 52 and 26 weeks, respectively. Here is how we can do the split using lifetimes:

We see that now each customer is associated with both calibration features for model training and holdout (observation period) features for model validation.
In lifetimes, the model fitting follows the familiar scikit-learn steps of instantiating a model object (which optionally includes hyperparameter setup) and fitting it to the calibration (training) data:
That’s it — two lines and we have a working BG-NBD model!
As you might remember from the first article, a BG-NBD model is composed of a Gamma and a Beta distribution. The parameters r and α of the Gamma distribution and a and b of the Beta distribution are accessible through the .summary attribute of the fitted model object:

In the next section, we'll derive some business insights from these parameters.
Assessment of model fit by comparing model-generated artificial data and real data
The adage of “garbage-in, garbage-out” applies to BG-NBD modeling: relying on a poorly-fitted model can lead to disastrous business decisions. As such, before making predictions and interpretations using our model, we should first assess the model’s performance. lifetimes provides a couple of ways of assessing our model. The first is to compare the frequencies between our real calibration data and artificial data sampled from the distributions generated by the BG-NBD model. The function plot_period_transactions does this in one line:

The plot shows that the distribution of frequencies in the training data largely agrees with that artificially generated by our fitted model. This suggests that the physical process that we assume to have generated our data is captured pretty well by our model.
One of the main goals behind fitting the BG-NBD model is to make predictions. In this section, we'll see how predictions can be generated and subsequently used to further assess the performance of the model. When given a customer with specific frequency, recency and T, a fitted model object can generate two types of predictions:
Let’s see an example of how this can be done. First, we’ll select a sample customer and inspect his frequency, recency and T for both the calibration and the observation periods:

We see that during the observation period, the customer made 2 + 1 = 3 transactions (the “+ 1” comes from converting the number of repeat transactions, which exclude the first transaction, to total transactions).
Let's now compare this “real” number to the prediction generated by BG-NBD. The following code yields an expected number of transactions the customer will make in the next 26 weeks (the length of the observation period)²:
We see that the predicted transaction number (0.76 transactions) is lower than the actual one (3 transactions).
We can similarly predict the probability that a certain customer is still active/alive at the end of the calibration period/start of the observation period).³
Since the customer did make some purchases in the observation period, we know with absolute certainty that he was active at the end of the calibration period. As such, the predicted probability of 0.57 is an underestimate.
Having seen how to make number-of-transactions prediction for one individual, we can extend the procedure to our whole customer base. The resulting predictions can then be compared with the real transaction data to gauge the accuracy of our model.

If a more rigorous assessment is desired, these two columns can be subjected to typical regression metrics such as RMSE:
Once we are satisfied with the performance of our model, we can proceed to derive insights from it. A good starting point would be the extraction and visualization of the estimated Gamma and Beta parameters. As elaborated in the previous article, the Gamma and Beta distributions carry important business significance. The Gamma distribution tells us about the distribution of the transaction rates of our customer base, while the Beta distribution reflects the distribution of probability-to-deactivate.
The code below shows how to extract the Gamma and Beta parameters from the model and plot the distribution:

From the plot, we can see that the Gamma distribution is relatively healthy, with most of the 𝜆 found near 2. This means our customers are expected to shop at a rate of 2 transactions per week.

The Beta distribution also seems healthy, with most of the p found near 0. This implies that our customers are unlikely to deactivate soon.
In addition to the model-fit assessment described, the fitted model object can also be used for some interpretative analysis.
For example, we can look at its Frequency/Recency/Future Purchases Matrix. This matrix shows how different frequency-recency combinations give rise to different expected numbers of future purchases.

As we can see, our best customers are in the bottom right corner — these peeps made frequent purchases pretty recently, so we have a high expectation that they’ll come back.
On the contrary, our least promising customers are in the top right corner — they made frequent purchases and then stopped coming and we haven’t seen them in months. It is likely that they’ve found another store (i.e. they’ve deactivated).
Similarly, we can also produce the Frequency/Recency/Probability Alive Matrix. This matrix shares the same axes as the previous one, but now the shade of each cell tells us the alive probability of customers with various frequency-recency combinations.

Unsurprisingly, we can see similar patterns, in which the best and the worst customers are in the top right and the bottom right of the matrix, respectively.
We’ve seen how we could use the BG-NBD model to predict the probability-of-being-alive p as well as number of purchases in the next k periods. These two predictions can in turn be used to calculate a rough estimate of the customer’s value for the next k periods. The estimate can be calculated as follows:

This estimate relies on the following two simplistic assumptions:
Do note that these naive assumptions have weak theoretical underpinnings — in reality, p usually changes after every purchase and the future purchase value might diverge significantly from the past values. As such, the resulting estimate is a rough one. Should you be interested, more sophisticated probabilistic models such as the Gamma-Gamma model exist that can calculate the future purchase value in a more rigorous manner⁴.
This is how we perform the above calculation in Pandas:
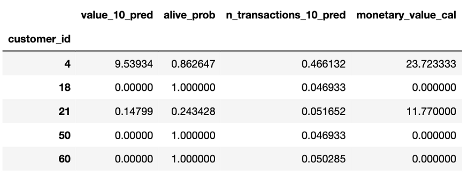
The resulting value_10_pred column encapsulates the estimated value of our customers for the next 10 weeks. We can then use this estimate to measure the health of our business. For example, we can obtain summary statistics of value_10_pred:

We see that on average, we’d expect customers to spend around $5.18 in the next 10 weeks.
We can also plot a histogram:

We see that a big chunk of our customers have value_10_pred close to 0. The resulting average of $5.18 was driven by a few outliers (a handful of customers with a very high value_10_pred). In the next section, we'll see how to make use of this information.
These three new columns, alive_prob, n_transactions_10_pred and value_10_pred, crystalize and quantify aspects of our customers that were previously invisible. Apart from being informational, these new features can be used to drive concrete actions. For example, we can use these new features to selectively and proactively reach out to different segments of our customers with the goal of increasing their expected CLV.
We've previously concluded that our overall customer value is largely attributable to a few high value customers. As these customers are our revenue drivers, we'd want to pay special attention to them. One idea is to occasionally send them congratulatory messages/vouchers to encourage their continuous loyalty.

Another idea is to contact customers with high probability of churning (i.e. those with low probability of being alive) to discourage them from abandoning our business.
As we've seen before, value_10_pred estimates the amount of purchases that our customers will make in the next ten periods. Another way to make use of this is to support our supply chain decision (e.g. stock replenishing).
Words of caveat: the BG-NBD was not conceived as a time-series model; it is not equipped with time-series features such as the accounting of seasonality and trend. As such, when it comes to forecasting, it would be prudent to not only rely on the forecasts made by BG-NBD and rather combine it with time series models such as ARIMA.
We’ve seen how lifetimes allows us to conveniently understand the purchasing behavior of our customer base and derive powerful and actionable insights from it.
While this is awesome, keep in mind that the estimations from lifetimes are maximum likelihood estimations that are inferred purely from the data we supply.
In the third article of the series, I will show you an alternative way to implement BG-NBD, this time using Bayesian hierarchical modeling powered by PyMC3. We'll see that this implementation offers more flexibility as it allows us to introduce domain knowledge into the modeling step.
I hope to see you there!


